Architecture Guide
Understanding FinWorld's seven-layer architecture and component interactions
Seven-Layer Architecture
FinWorld employs a hierarchical, layered architecture with object-oriented design principles to ensure clear separation of concerns and facilitate both flexibility and scalability across the platform. This modular seven-layer architecture enables seamless integration of multiple AI paradigms including traditional ML, DL, RL, LLMs, and LLM agents.
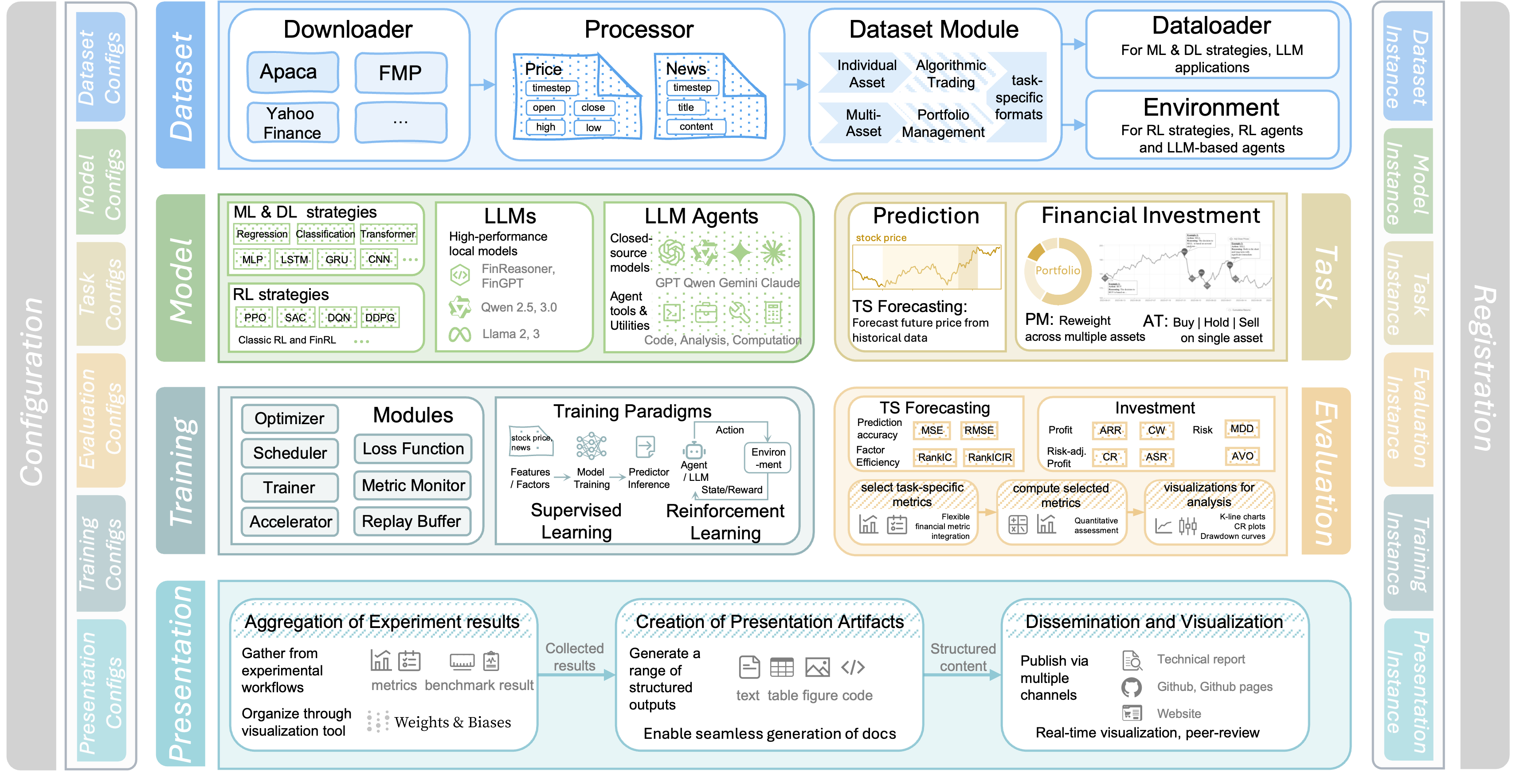
Figure 1: FinWorld's comprehensive seven-layer architecture
Why Seven Layers?
The seven-layer design addresses the complexity of financial AI systems by providing:
- Clear Separation of Concerns - Each layer handles specific responsibilities without overlap
- Modular and Decoupled Design - Components are self-contained with well-defined interfaces
- Extensibility and Paradigm Fusion - Standardized extension points for novel algorithms and datasets
- Unified Interface - Consistent APIs across different AI paradigms
- Reproducibility - Standardized configuration and evaluation protocols
Layer Overview
- Configuration Layer - Centralizes all experiment and system settings for reproducibility
- Dataset Layer - Handles data collection, preprocessing, and management for various financial datasets
- Model Layer - Supports multiple paradigms (ML, DL, RL, LLMs, LLM Agents) for flexible modeling
- Training Layer - Oversees training, hyperparameter tuning, and distributed learning
- Evaluation Layer - Provides standardized evaluation protocols and metrics for financial applications
- Task Layer - Defines and organizes financial tasks for rapid prototyping and extension
- Presentation Layer - Enables visualization, reporting, and interactive analysis of results
Configuration Layer
The configuration layer is built on mmengine and provides a unified and extensible system using dictionaries. It centralizes all experimental settings, including datasets, models, training, and evaluation, in a readable and modular format.
Key Features
- Unified Configuration - All experimental settings in one place
- Configuration Inheritance - Support for configuration inheritance and overrides
- Registry Mechanism - Manages core components by type
- Reproducibility - Ensures experiment reproducibility and collaborative development
Dataset Layer
The dataset layer comprises multiple functional modules designed to enable standardized, extensible, and task-oriented data management for financial AI research. It abstracts the complexities of diverse data sources and modalities, offering a unified interface for data acquisition, preprocessing, and task-specific organization.
Key Modules
- Downloader Module - Market data downloaders (FMP, Alpaca) and LLM reasoning dataset downloaders
- Processor Module - Factor computation (alpha158), feature selection, and normalization
- Dataset Module - Task-specific data organization for trading, portfolio, and multi-asset problems
- Dataloader Module - Standardized dataloaders for ML, DL, and LLM applications
- Environment Module - Interactive environments for RL paradigms and LLM-based agents
Model Layer
The model layer consists of multiple specialized modules that enable unified definition, management, and invocation of diverse modeling paradigms within the platform. It abstracts the construction and orchestration of traditional ML models, deep neural networks, and LLMs, providing standardized interfaces for consistent training, inference, and integration across multi-tasks.
Model Categories
- ML Models - Linear/logistic regression, decision trees, random forests, gradient boosting (XGBoost, LightGBM)
- DL Models - Neural architectures with components, layers, and networks (Autoformer, VAE, GPT-style decoders)
- RL Models - Actor-critic abstraction with policy and value networks, financial constraints
- LLMs Models - Unified interface for proprietary and open-source LLMs (GPT-4.1, Claude-4-Sonnet, Qwen2.5)
Training Layer
The training layer offers a modular scaffold that abstracts every element required to optimize all method pipelines for financial applications. A uniform interface guarantees experiment reproducibility, smooth scaling from single GPU notebooks to distributed clusters, and quick transfer of best practices across tasks.
Key Components
- Optimizer - Rich catalogue of first-order methods (SGD, Adam, AdamW) with gradient centralization and mixed precision
- Loss - Flexible factory for regression, classification, and RL surrogate objectives
- Scheduler - Static and adaptive strategies for learning rates and regularization
- Metrics - Finance-specific diagnostics (ARR, SR, MDD) with configurable logging
- Trainer - Orchestrates data loading, training loops, and experiment logging
Evaluation Layer
The evaluation layer provides a comprehensive and extensible framework for assessing financial AI models and strategies. It dynamically selects and applies appropriate evaluation protocols and metrics based on the specific task and model type, supporting both established benchmarks and user-defined criteria.
Key Features
- Financial Metrics - ARR, MDD, SR, MSE with flexible combination and extension
- Visualization Tools - Candlestick charts, cumulative return plots, drawdown curves, trade annotations
- Systematic Comparison - Supports systematic comparison, diagnosis, and iterative improvement
- Integration - Integrated into trainer's validation and test stages
Task Layer
The task layer is responsible for the systematic definition, abstraction, and encapsulation of financial AI task types. It systematically supports a wide spectrum of financial AI tasks, providing unified abstractions and modular interfaces that facilitate integration with upstream data modules and downstream modeling components.
Core Tasks
- Time Series Forecasting - Predictive modeling for financial time series
- Algorithmic Trading - Automated trading strategy development
- Portfolio Management - Multi-asset portfolio optimization
- LLM Applications - Financial reasoning and LLM-based agent training
Presentation Layer
The presentation layer is designed for automated dissemination and documentation of experimental results. It orchestrates the aggregation of evaluation outputs, automatic generation of technical reports, and the creation of interactive web pages for result interpretation and dissemination.
Key Features
- Automated Reporting - Automatic generation of technical reports and documentation
- Interactive Web Pages - Creation of interactive result interpretation pages
- Platform Integration - Seamless integration with GitHub, WandB, and other collaborative platforms
- Real-time Visualization - Live visualization and comparison of metrics throughout research lifecycle