AlphaForgeBench: Benchmarking End-to-End Trading Strategy Design with LLMs
We introduce AlphaForgeBench, a benchmark for evaluating LLMs as quantitative researchers — generating executable alpha factors and trading strategies, evaluated via standardized backtesting across seven assets and six frontier models.
We introduce AlphaForgeBench, accepted at KDD 2026, a benchmark that repositions LLMs from direct trading agents to quantitative researchers — tasked with generating executable alpha factors and strategy code, evaluated via rigorous standardized backtesting.
The Problem: LLMs as Trading Agents Are Unstable
Prior work on LLM-based financial evaluation often asks models to emit trading actions directly. This approach suffers from a fundamental problem: behavioral instability during sequential decision-making. LLMs manifest extreme run-to-run variance, inconsistent action sequences under deterministic decoding, and irrational action reversals in adjacent decision steps. These instabilities make fair benchmarking nearly impossible.
AlphaForgeBench solves this by separating financial reasoning from execution: LLMs generate strategy code and alpha factors rather than individual trades, and a deterministic backtesting engine handles execution.
Framework
The benchmark is built on a two-stage dataset construction pipeline:
Stage 1 — Real-world queries (633 samples): Natural-language financial queries paired with ground-truth alpha factors and trading strategies sourced from real-world quantitative research.
Stage 2 — Augmented queries (270 samples): LLM-generated queries following a 3×3 level-grade taxonomy that progresses from direct translation to open-ended strategy design under controlled difficulty. This systematic structure enables measuring how model capability scales with task complexity.
Evaluation Pipeline
| Step | Description |
|---|---|
| Query submission | Natural-language strategy request sent to the model |
| Code generation | Model produces executable alpha factor / strategy code |
| Backtesting | Standardized engine runs code across 7 assets and multiple market regimes |
| Metrics | SR, ARR, MDD, Calmar Ratio, Sortino Ratio, Volatility |
The benchmark covers 7 assets (cryptocurrency and US equities), 6 frontier LLMs, and 35,190 total implementations — making it the most comprehensive LLM trading evaluation to date.
Results
Stage 1 — Real-World Queries
| Model | SR ↑ | ARR ↑ | MDD ↓ | Calmar ↑ |
|---|---|---|---|---|
| gemini-3-pro-preview | 0.449 | 0.171 | 0.174 | 1.411 |
| gemini-3-flash-preview | 0.388 | 0.142 | 0.138 | 1.504 |
| claude-sonnet-4.5 | 0.378 | 0.138 | 0.138 | 1.456 |
| grok-4.1-fast | 0.366 | 0.135 | 0.142 | 1.396 |
| gpt-5.2 | 0.342 | 0.123 | 0.122 | 1.534 |
| deepseek-v3.2 | 0.329 | 0.116 | 0.114 | 1.575 |
Stage 2 — LLM-Augmented Queries (τ = 0.7)
| Model | SR ↑ | ARR ↑ | MDD ↓ | Calmar ↑ |
|---|---|---|---|---|
| gemini-3-pro-preview | 0.627 | 0.209 | 0.188 | 1.639 |
| gemini-3-flash-preview | 0.530 | 0.165 | 0.151 | 1.658 |
| claude-sonnet-4.5 | 0.508 | 0.162 | 0.147 | 1.634 |
| grok-4.1-fast | 0.429 | 0.135 | 0.127 | 1.692 |
| deepseek-v3.2 | 0.424 | 0.130 | 0.123 | 1.570 |
| gpt-5.2 | 0.417 | 0.130 | 0.117 | 1.660 |
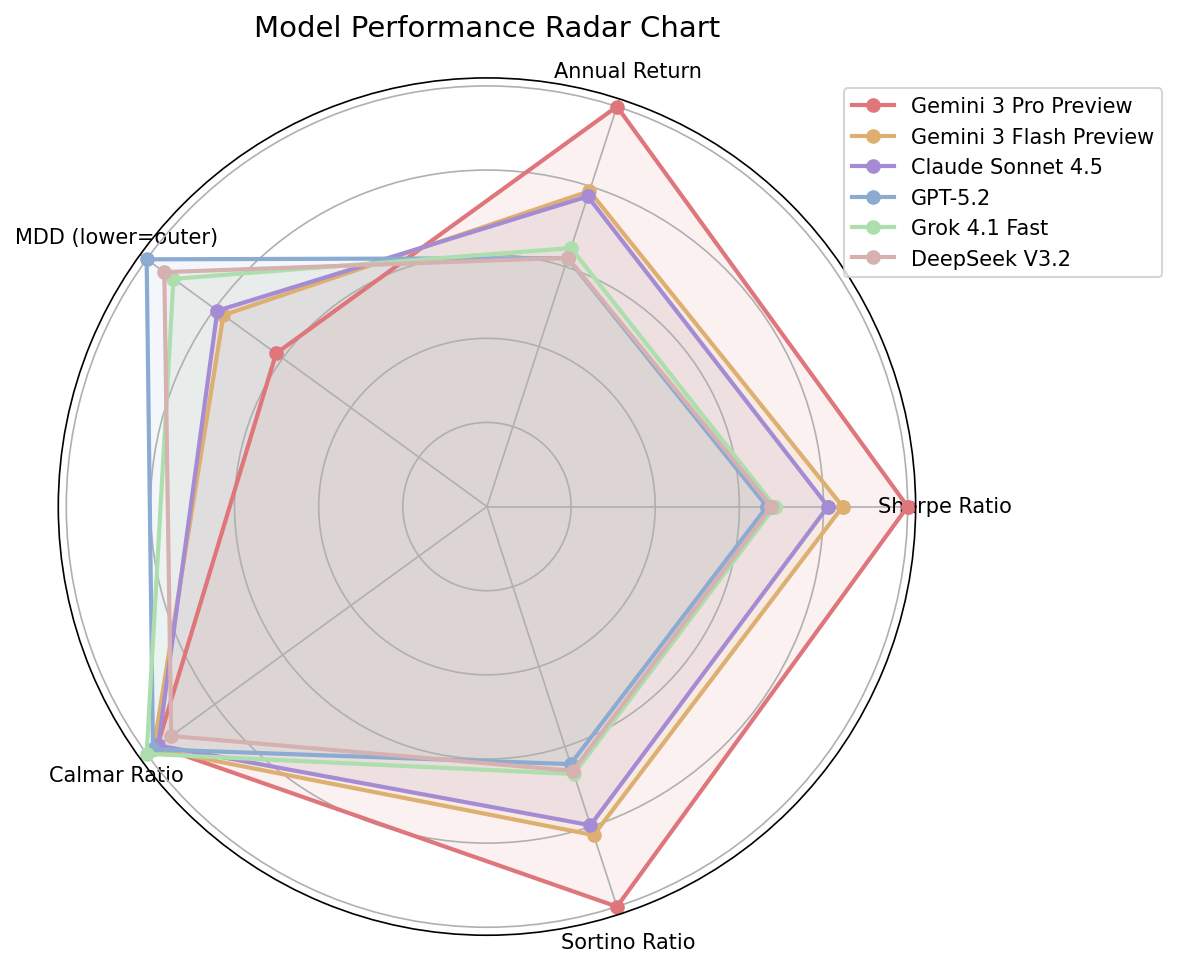
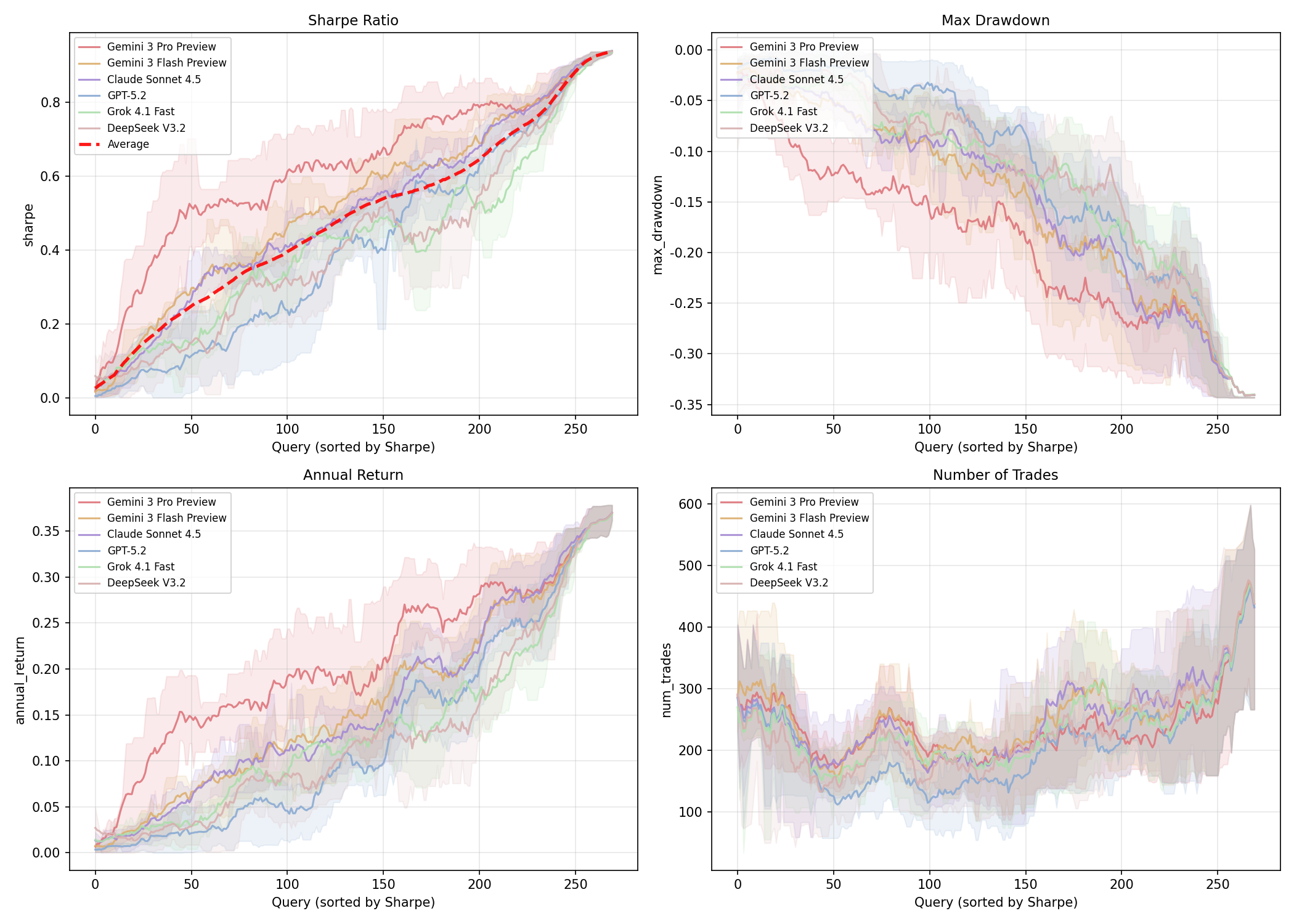
Key Findings
Temperature invariance: Results at τ = 0 and τ = 0.7 are near-identical across models, validating that the code-generation framing eliminates the run-to-run variance that plagues direct action-generation approaches.
Systematic difficulty scaling: Inter-model performance spread widens monotonically from Level 1 (direct translation) through Level 3 (open-ended design), confirming the benchmark effectively stress-tests different capability levels.
Cross-level ranking reversals: Models strong at translating existing strategies don’t necessarily excel at open-ended strategy design — suggesting the two skills are distinct and worth evaluating separately.
Three persistent risk profiles: Aggressive (high return, high drawdown), balanced-stable, and conservative-rigid archetypes emerge across models and persist across evaluation conditions.
Links
- Paper: arXiv:2602.18481
- GitHub: finbrain-lab-hkustgz/AlphaForgeBench
- Project Page: finbrain-lab-hkustgz.github.io/AlphaForgeBench
